Flatlander
Species Developer
I am making this tutorial to go along with my Monster View-Range Tutorial.
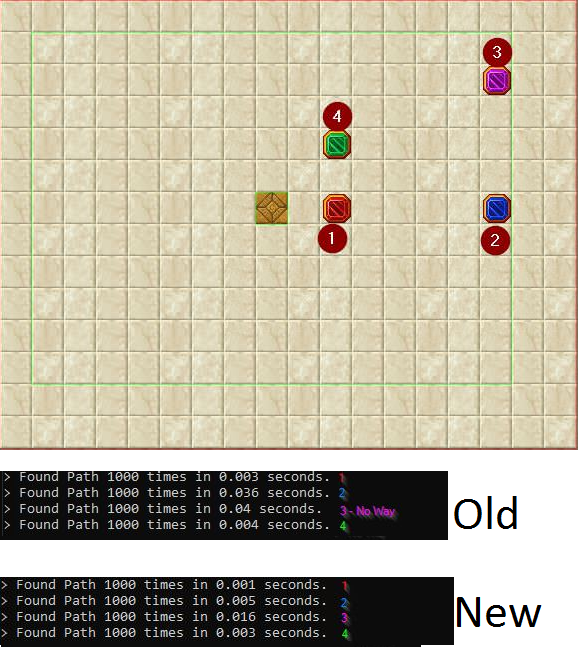
When adding more view-range to a monster, you quickly find your server is constantly freezing due to path-finding. (Especially if you are like me and want wolves to stalk your poor players from 50 tiles away)
To fix this, I added a bit more optimization to the Pathfinding in TFS.
Below is how you can also make these changes.
(I am self-taught, what I do does work, but it might not be the most efficient and best way to do it, if someone else knows how to make my code even more optimized please criticize and teach me how)
First we need to be able to pull the Target Position while in BestNode to help calculate the true "best node".
In Creature.cpp edit the following:
Add targetPos into getPathMatching after *this,
In map.h edit the following:
Add targetPos here too:
And also in map.h edit the following:
Adding targetPos here too:
In map.cpp edit the following:
Add targetPos here too:
Then edit this BestNode in map.cpp:
To include targetPos:
And now for the big edit, the getBestNode() function itself:
Change it to the above (I have comments on why each line exists)
The above SHOULD work.
The only thing that may be done incorrectly is getting the pos.x and pos.y from the Nodes[] (I do this differently in TFS 0.X, but tried to use the same way TFS 1.X has it done)
AFTER you do this, you should be able to go to my next tutorial adding monster ViewRange to the monsters.xml so you can have monsters that see farther than screen-size.
When adding more view-range to a monster, you quickly find your server is constantly freezing due to path-finding. (Especially if you are like me and want wolves to stalk your poor players from 50 tiles away)
To fix this, I added a bit more optimization to the Pathfinding in TFS.
Below is how you can also make these changes.
(I am self-taught, what I do does work, but it might not be the most efficient and best way to do it, if someone else knows how to make my code even more optimized please criticize and teach me how)
First we need to be able to pull the Target Position while in BestNode to help calculate the true "best node".
In Creature.cpp edit the following:
Code:
bool Creature::getPathTo(const Position& targetPos, std::forward_list<Direction>& dirList, const FindPathParams& fpp) const
{
return g_game.map.getPathMatching(*this, dirList, FrozenPathingConditionCall(targetPos), fpp);
}
Code:
bool Creature::getPathTo(const Position& targetPos, std::forward_list<Direction>& dirList, const FindPathParams& fpp) const
{
return g_game.map.getPathMatching(*this, targetPos, dirList, FrozenPathingConditionCall(targetPos), fpp);
}In map.h edit the following:
Code:
bool getPathMatching(const Creature& creature, std::forward_list<Direction>& dirList,
const FrozenPathingConditionCall& pathCondition, const FindPathParams& fpp) const;
Code:
bool getPathMatching(const Creature& creature, const Position& targetPos, std::forward_list<Direction>& dirList,
const FrozenPathingConditionCall& pathCondition, const FindPathParams& fpp) const;And also in map.h edit the following:
Code:
AStarNode* getBestNode();
Code:
AStarNode* getBestNode(const Position& targetPos);In map.cpp edit the following:
Code:
bool Map::getPathMatching(const Creature& creature, std::forward_list<Direction>& dirList, const FrozenPathingConditionCall& pathCondition, const FindPathParams& fpp) const
Code:
bool Map::getPathMatching(const Creature& creature, const Position& targetPos, std::forward_list<Direction>& dirList, const FrozenPathingConditionCall& pathCondition, const FindPathParams& fpp) constThen edit this BestNode in map.cpp:
Code:
AStarNode* found = nullptr;
while (fpp.maxSearchDist != 0 || nodes.getClosedNodes() < 100) {
AStarNode* n = nodes.getBestNode();
Code:
AStarNode* found = nullptr;
while (fpp.maxSearchDist != 0 || nodes.getClosedNodes() < 100) {
AStarNode* n = nodes.getBestNode(targetPos);And now for the big edit, the getBestNode() function itself:
Code:
AStarNode* AStarNodes::getBestNode()
{
if (curNode == 0) {
return nullptr;
}
int32_t best_node_f = std::numeric_limits<int32_t>::max();
int32_t best_node = -1;
for (size_t i = 0; i < curNode; i++) {
if (openNodes[i] && nodes[i].f < best_node_f) {
best_node_f = nodes[i].f;
best_node = i;
}
}
if (best_node >= 0) {
return nodes + best_node;
}
return nullptr;
}
Code:
AStarNode* AStarNodes::getBestNode(const Position& targetPos)
{
if (curNode == 0) {
return nullptr;
}
int32_t diffNode = 0; //Difference between nodes
int32_t best_node_f = std::numeric_limits<int32_t>::max();
int32_t best_node = -1;
for (size_t i = 0; i < curNode; i++) {
//I am not familiar with 1.X so there is probably a better way to get all these variables, also the below is the untested in TFS 1.X, hope it works
const int_fast32_t Sx = nodes[0].x; //Starting X Position
const int_fast32_t Sy = nodes[0].y; //Starting Y Position
const int_fast32_t Cx = nodes[i].x; //node[i] X Position
const int_fast32_t Cy = nodes[i].y; //node[i] Y Position
int32_t SdiffX = std::abs(targetPos.x - Sx); //X distance from the starting location
int32_t SdiffY = std::abs(targetPos.y - Sy); //Y distance from the starting location
int32_t NdiffX = std::abs(targetPos.x - Cx); //X distance from node[i] position
int32_t NdiffY = std::abs(targetPos.y - Cy); //X distance from node[i] position
diffNode = ((nodes[i].f+(((NdiffX-SdiffX)*5)+((NdiffY-SdiffY)*5)))+(std::max(NdiffX, NdiffY)*5)); //I messed around with this formula a lot to try to get the best performance, for me this works the best
if (openNodes[i] && diffNode < best_node_f) { //Compares the formula above with the current Best Node
best_node_f = diffNode; //Sets the Best Nodes new value to beat
best_node = i;
}
}
if (best_node >= 0) {
return nodes + best_node;
}
return nullptr;
}The above SHOULD work.
The only thing that may be done incorrectly is getting the pos.x and pos.y from the Nodes[] (I do this differently in TFS 0.X, but tried to use the same way TFS 1.X has it done)
AFTER you do this, you should be able to go to my next tutorial adding monster ViewRange to the monsters.xml so you can have monsters that see farther than screen-size.
Last edited:





")

